
Three Steps for OCaml to Crest the AI Humps
I gave the talk "Three Steps for OCaml to Crest the AI Humps" at the 2025 OCaml Workshop at ICFP/SPLASH. In it I discussed the challenges and opportunities for OCaml in the age of AI coding assistants.
You can find a video of the talk here. There's also an extended abstract. This blog post has a copy of the slides along with some commentary taken from the speaker notes and other links.
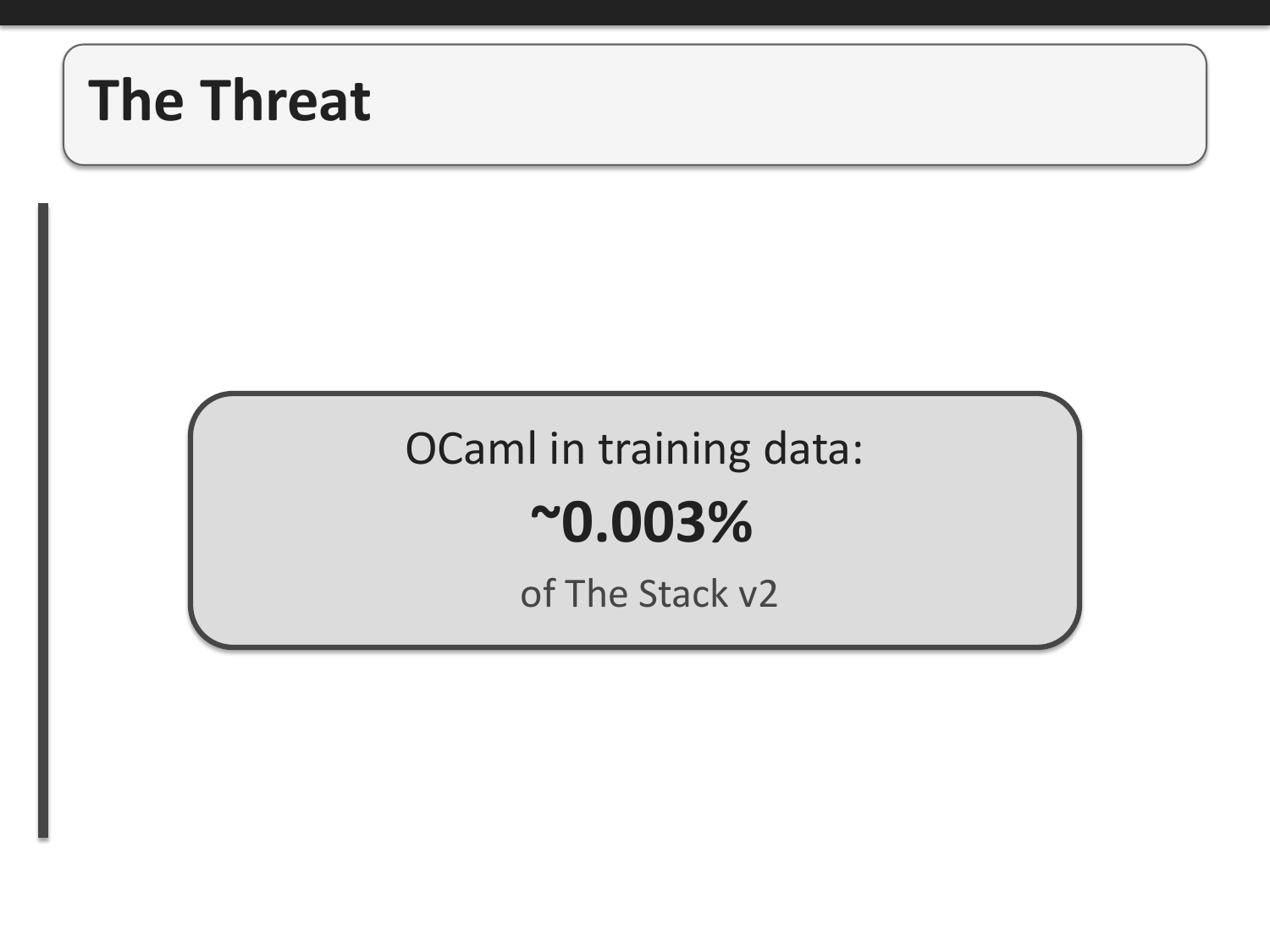
OCaml represents approximately 0.003% of The Stack v2, a major code corpus used for training large language models. Compare this to Python, which makes up about 8% of the same dataset. There are consequences for having so little data available..

The disparity translates in a difference in problem solving ability between languages. Cassano et al found a 5x difference in Pass@1 HumanEval performance using Starcoder 15B between OCaml and Python. This performance gap has real consequences for developer productivity.

The gap between coding agent performance on mainstream versus niche languages could prove fatal to smaller language communities. New developers increasingly judge a programming language not just on its traditional tooling (compilers, debuggers, libraries) but also on how well AI coding agents support it. If agents struggle with OCaml, fewer new developers will choose to learn it, creating a vicious cycle.

Rather than accept this fate, there are concrete steps the OCaml community can take to improve AI agent support. The talk outlines three actionable strategies that work together to address the training data gap and knowledge accessibility problems.

The first step is to systematically determine where AI agents are deficient for your specific, real-world use cases. You can't improve what you don't measure, and generic benchmarks might not capture the specific ways your community uses the language.

To measure agent performance, you first need to define what "well" means for your particular use case. Everyone has different use cases e.g sync vs async, hosted vs local, fine-tunable.

For our evaluation at Cambridge, we had specific requirements: the models needed to run locally or on university servers (no reliance on external APIs), support teaching environments (helping students learn, not just solving problems), be reproducible and have provenance, and be fine-tunable for our specific needs.
We chose to evaluate models using the first-year Computer Science Jupyter exercises ("ticks") from Cambridge's Foundations of Computer Science course. These exercises measure introductory CS problem-solving skills in OCaml and are directly relevant to our use case of supporting student learning. The exercises test concepts like recursion, data structures, and streams.
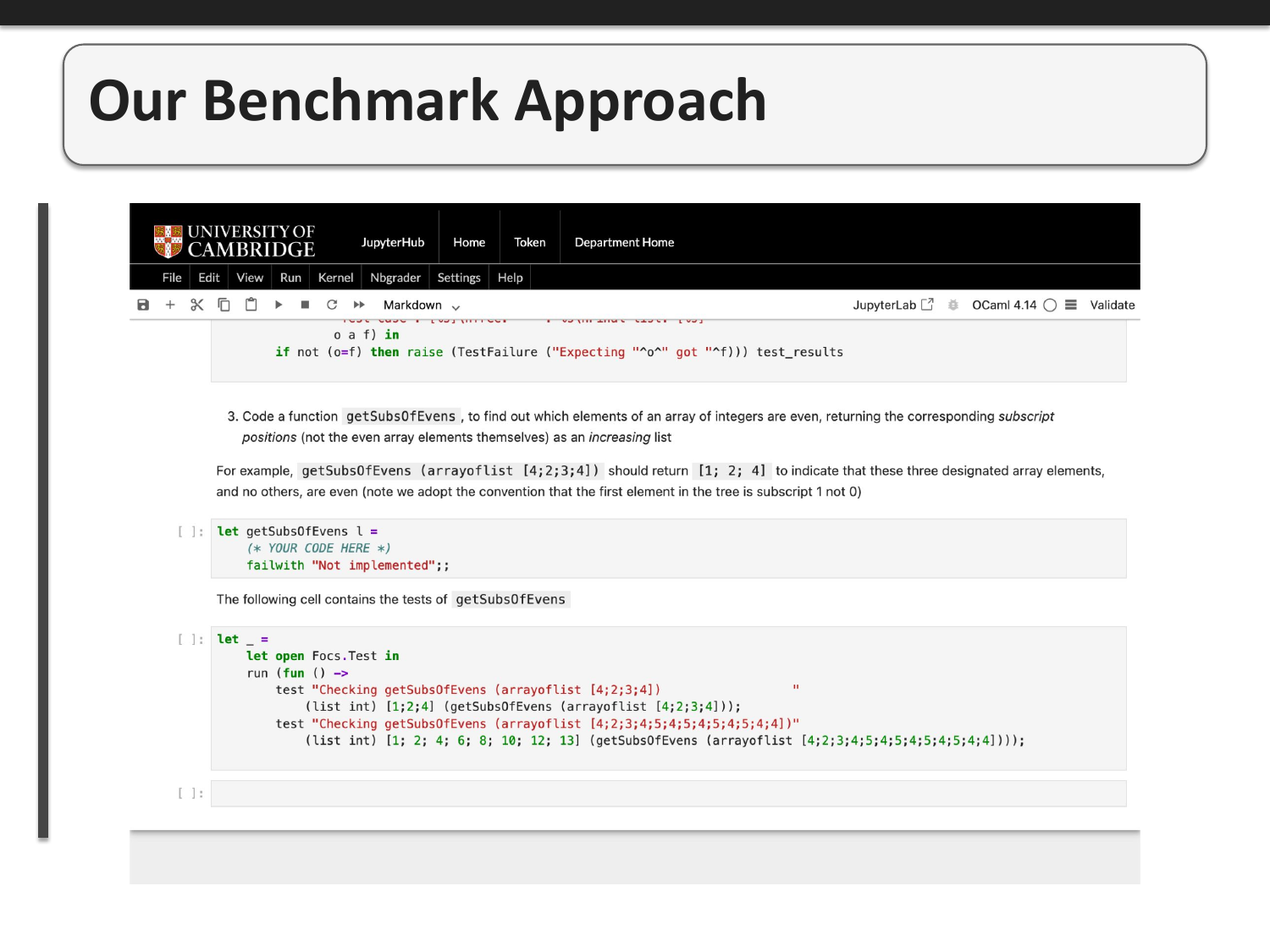
This slide shows an actual exercise from the benchmark. Students need to write a function getSubsOfEvens that returns the subscript positions of even integers in an array. The notebook provides test cases and automatically checks solutions - the same setup we used for evaluating AI models.
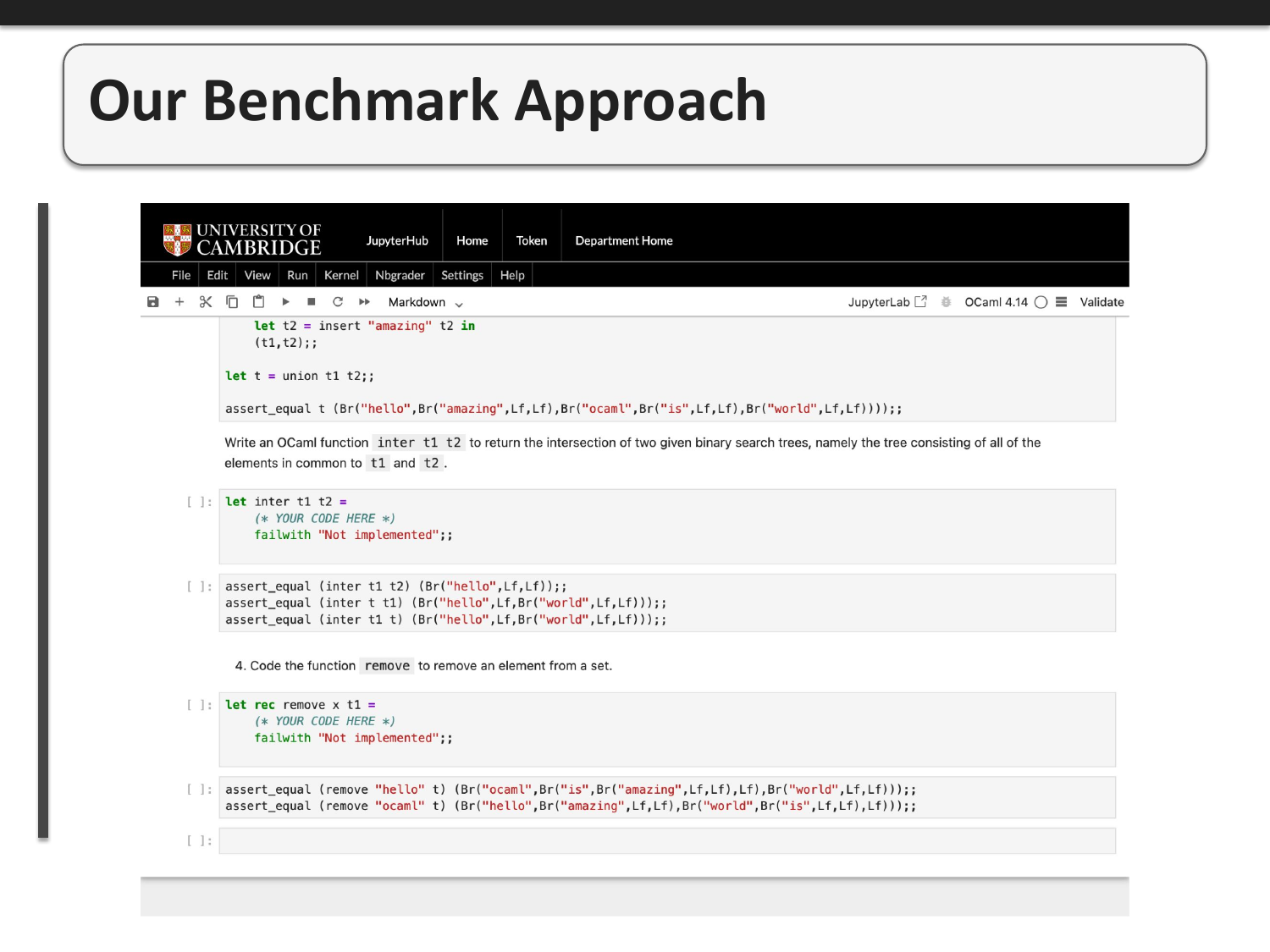
The exercises cover a range of computer science fundamentals. Here we see problems involving binary search tree operations (intersection) and set operations (remove). These test both algorithmic thinking and familiarity with OCaml's syntax and type system.
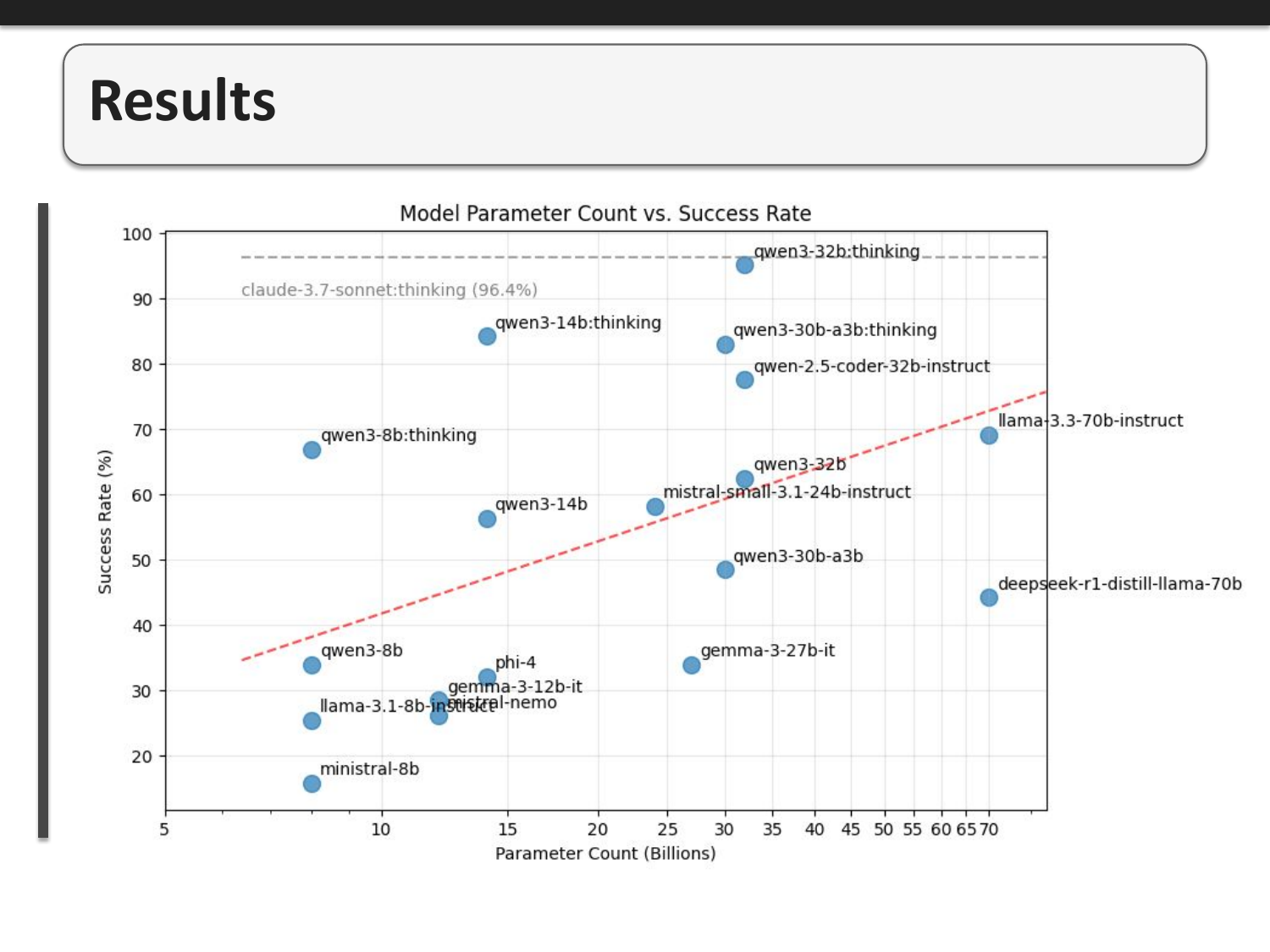
We benchmarked 19 different open-weight models, from 7B to 70B parameters. Within a family, larger models generally perform better, but there are interesting outliers. The Qwen3 family of models consistently perform well especially when using "thinking" mode. Claude-3.7-Sonnet (96.4%) sits at the top as our reference point for proprietary models.

Qwen3-32b with thinking mode achieved 94.2% success rate, nearly matching Claude-3.7 Sonnet's 96.4%. Without thinking mode, the same model scores only 62.4%. This demonstrates that reasoning significantly improves performance on OCaml tasks, and that, on this task, self-hostable models can achieve near-frontier performance when given space to reason. The cost is increased latency and higher token usage.

Smaller models frequently make syntax errors. Type system confusion is very common - using integer operators (like +) on floats is a recurring issue. Models hallucinate functions that don't exist in the standard library, such as List.sub or List.combinations, and often assume the Core library or Format module are available when they're not. Recursion errors are also frequent: forgetting the rec keyword, using incorrect base cases, or failing to make recursive progress.

Once you've identified deficiencies for your use cases, the second step is to contribute those tasks to public benchmarks. This is how you signal to AI labs what matters to your community.

AI organizations report performance on public benchmarks like SWE-bench and terminal-bench when releasing new models. They actively train their models to improve on these benchmarks. By adding OCaml-specific tasks that you care about to these benchmarks, you create an incentive for labs to improve their OCaml capabilities. If OCaml tasks are on the benchmark, models will get better at OCaml.
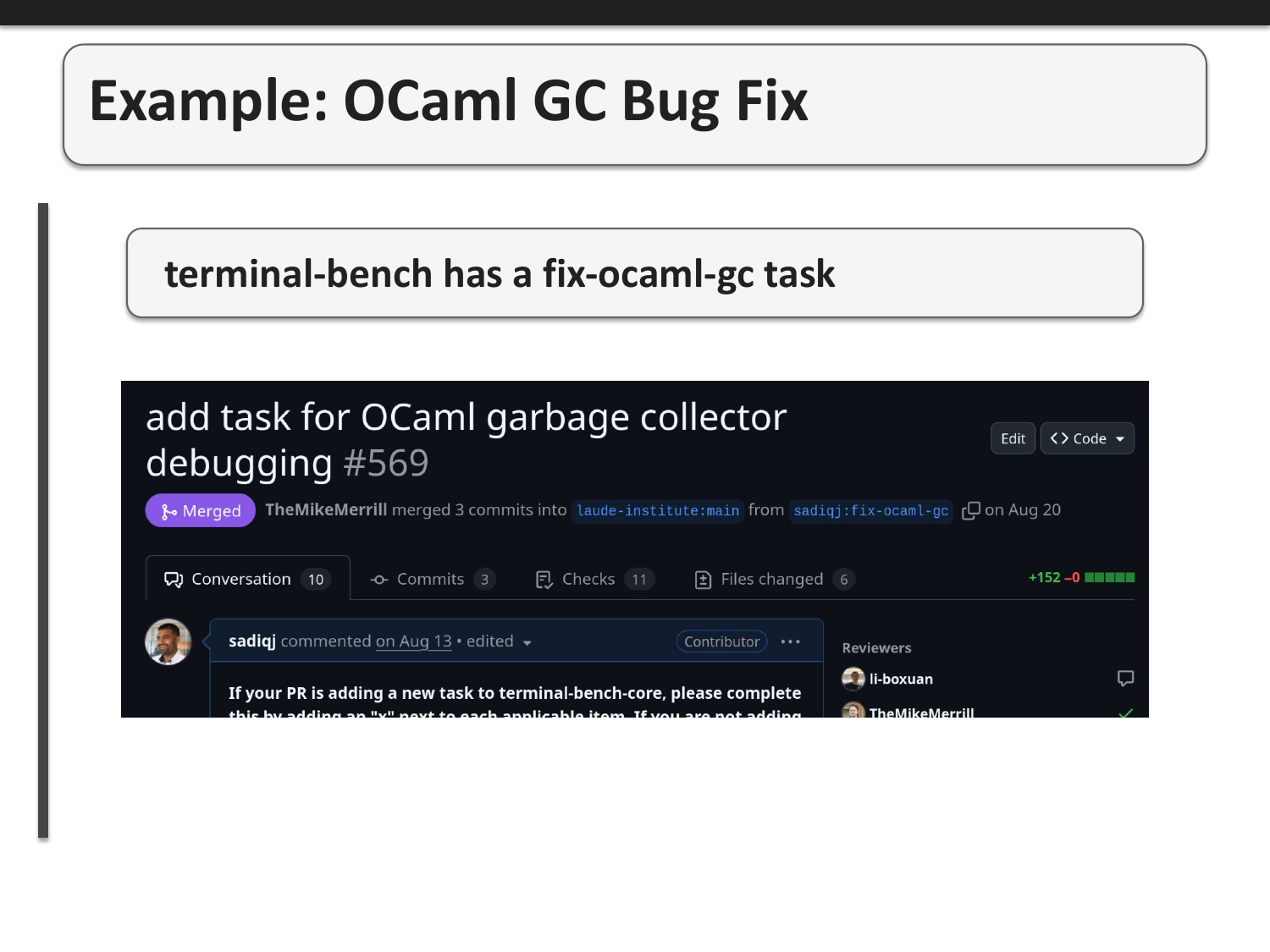
As a concrete example, I spend a significant amount of time debugging the garbage collector in OCaml and I found frontier models were still very poor at aiding me do that. So I contributed a task to terminal-bench that requires an agent to debug a segmentation fault in the OCaml garbage collector. In hindsight I worry this was a short-sighted career move (since I'm teaching agents to replace my debugging work).

The task is genuinely difficult and tests multiple capabilities: (1) build the OCaml compiler and runtime, (2) reproduce a GC failure, (3) debug with gdb, (4) patch C code, and (5) verify the fix. Completing this requires reading HACKING.adoc to understand the build system, navigating OCaml's runtime C code, and using debugging tools effectively - exactly the kind of complex, multi-step reasoning we want agents to excel at.
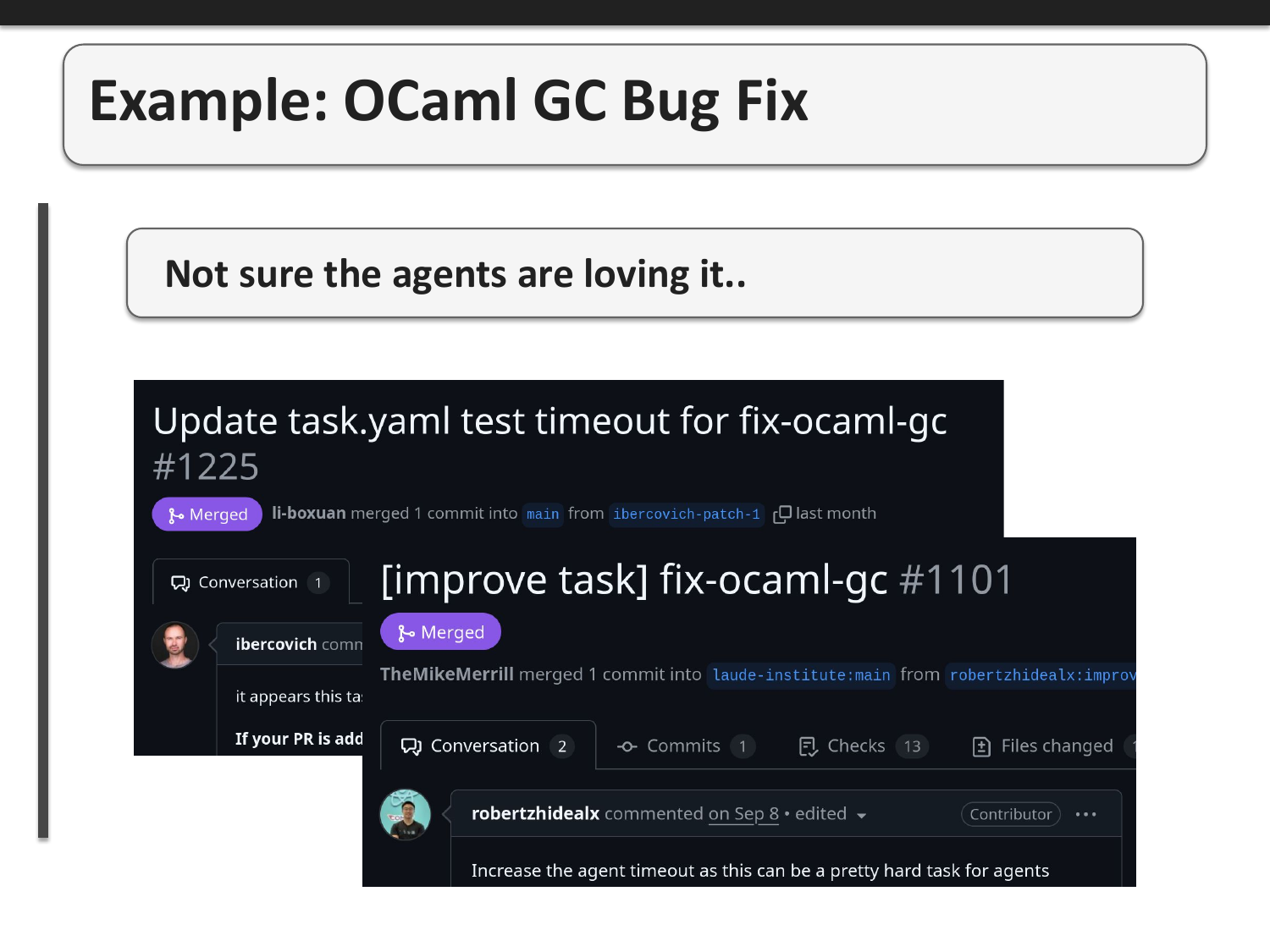
The task is proving quite difficult for agents. As evidenced by these GitHub PRs, the timeout for the fix-ocaml-gc task has been increased multiple times because agents are struggling to complete it within the time limit. This is actually good - it means the task is pushing the boundaries of current agent capabilities and driving improvement.

Contributing to benchmarks isn't a one-time activity. It needs to be done constantly because benchmarks eventually get "saturated" (models overfit to them) or are leaked into new training sets. The community needs to continuously create new, challenging tasks that represent real OCaml development work to maintain pressure on AI labs to improve their OCaml support.

The third step addresses the immediate problem: even if we can't add more OCaml to training data, we can bridge the knowledge gap by providing good agent-friendly tools and documentation. This can compensate for the lack of training exposure.

There are two main approaches: agent-friendly documentation and tools built on the Model Context Protocol (MCP). Documentation needs to be clean and parseable, while tools give agents the ability to search, discover, and navigate the OCaml ecosystem programmatically.
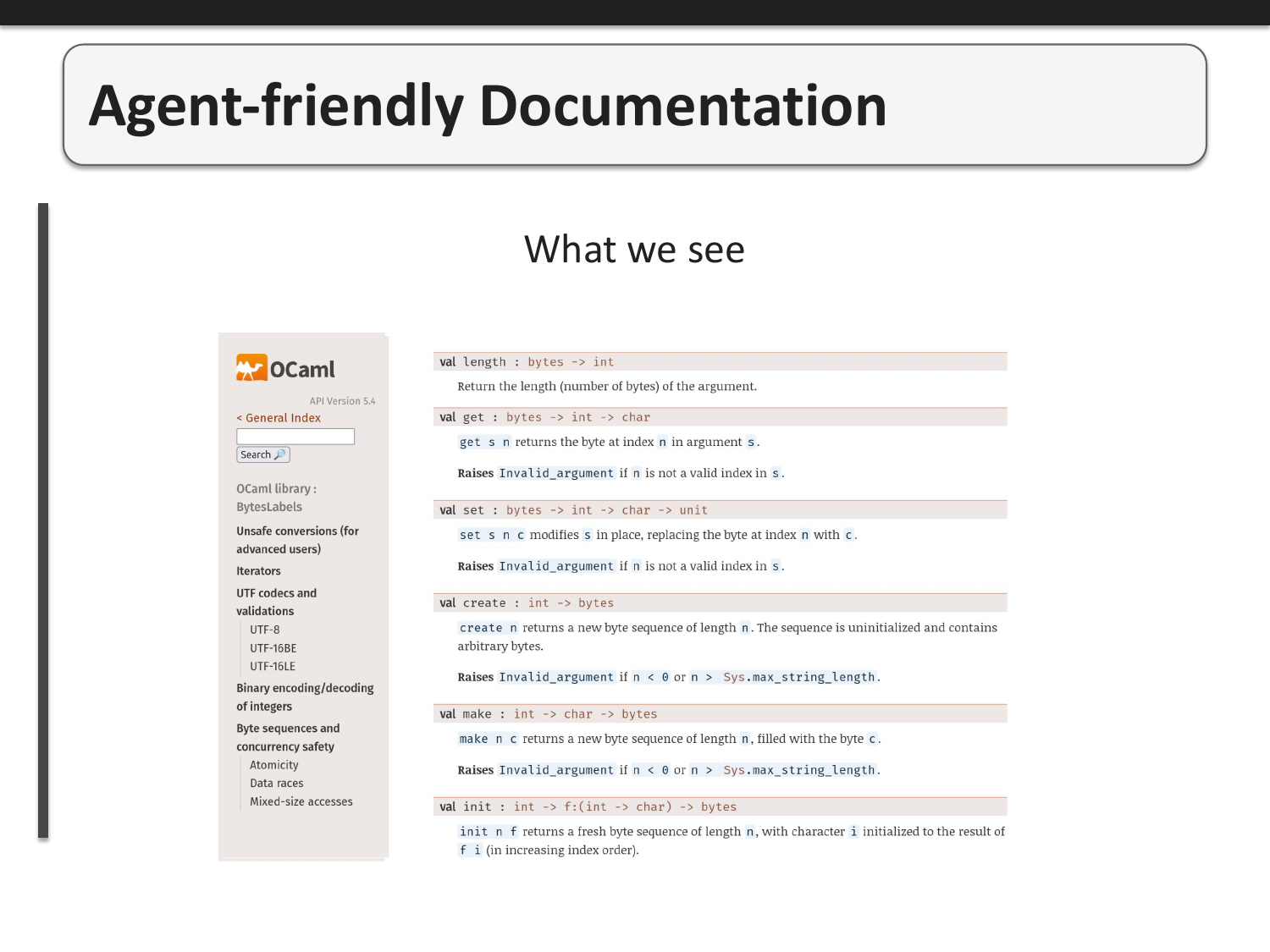
When we visit ocaml.org documentation, we see nicely formatted pages with the information we need. The HTML rendering makes it easy for humans to navigate and understand the API documentation.
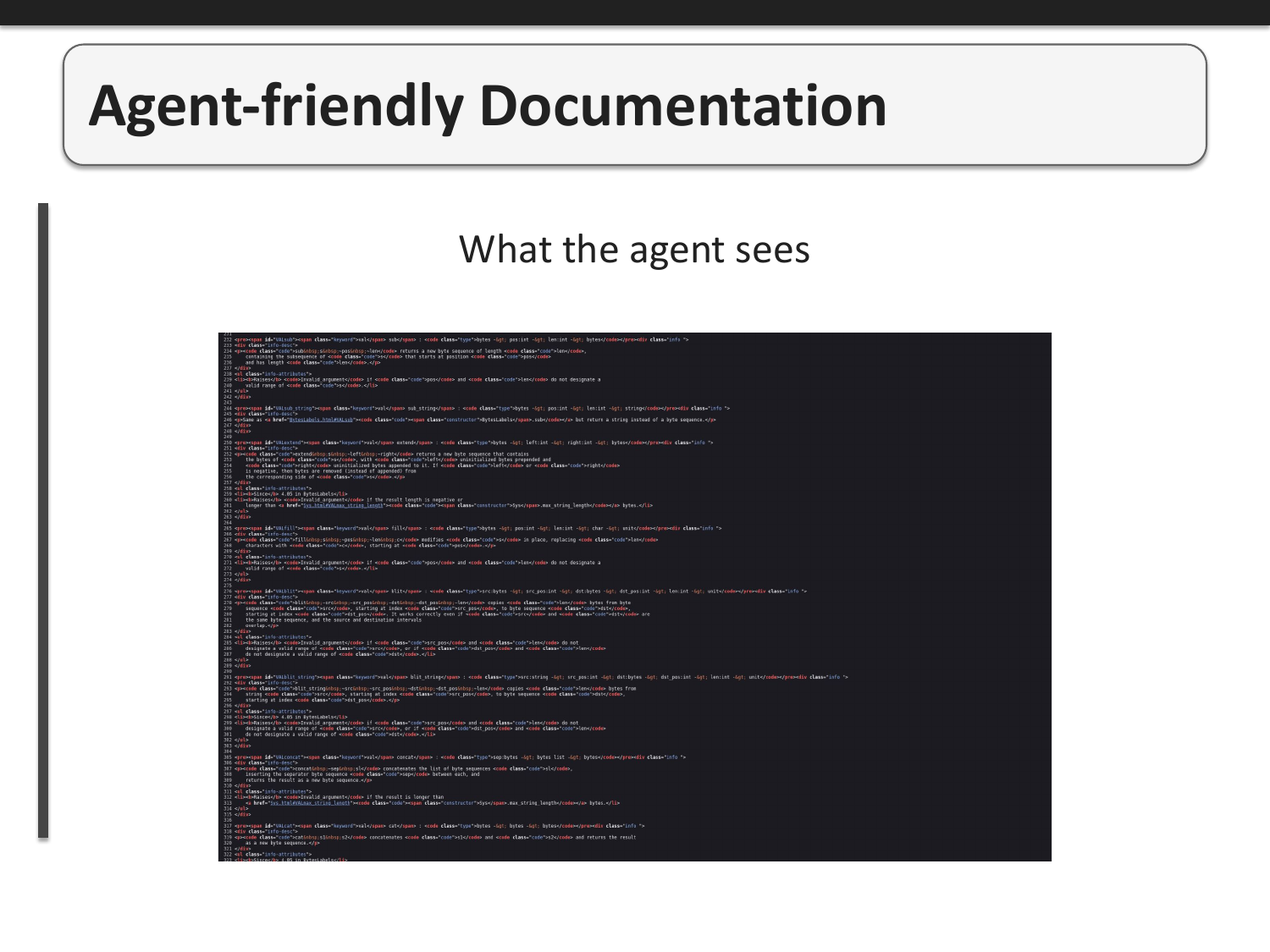
The problem is that when an agent accesses the same documentation, it sees a mix of content and messy HTML markup. This wastes valuable space in the model's limited context window and makes it harder to extract the relevant information. The signal-to-noise ratio is terrible for agents trying to understand OCaml APIs.

The solution is to provide clean, markdown-only versions of documentation. This gives agents the information they need without the HTML clutter. Recent improvements to odoc have merged the capability to generate markdown output, and emerging standards like LLMs.txt files provide additional ways to make documentation agent-accessible.
Beyond documentation, we can provide tools that agents can actively use. Along with Jon Ludlam I've built a prototype called odoc-llm that uses the Model Context Protocol to give agents a set of tools for interacting with the OCaml ecosystem. These tools allow agents to search for packages by functionality, get concise summaries of modules, and search through local project documentation using Sherlocode. This is critical for helping agents discover and use packages they were never trained on. The search uses a hybrid dense and sparse approach. Finding functionality in the OCaml ecosystem is genuinely hard, even for humans.

To summarize: the OCaml community can fight back against the existential threat posed by poor AI agent support through three concrete steps. First, determine where agents are deficient for your specific use cases through systematic evaluation. Second, contribute those use cases to public benchmarks to incentivize AI labs to improve. Third, bridge the knowledge gap with agent-friendly documentation and tools that compensate for the lack of training data. With these steps we can try to close the performance gap.