
Qwen3 Leads the Pack: Evaluating how Local LLMs tackle First Year CS OCaml exercises
TL;DR Qwen3's self-hostable sized models are very strong and would score top-marks on Cambridge's first year Computer Science OCaml exercises.
Large language models (LLMs) are transforming software development. What if you use a language outside the mainstream that has relatively little training data though? Worse, what if you want to use features that are still under development or only recently released? The model can't have seen those features during training and so won't make use of them when generating unless explicitly prompted to do so. My colleague Jon Ludlam, Anil Madhavapeddy and I have been thinking about this in the context of OCaml and some of the new extensions under development at Jane Street. Having a process for teaching models to use novel language features would not just be useful for interactive code generation but could also enable retrofitting existing codebases or if cheap enough, could be used in the design process for the features themselves.
Before we dived in though we wanted to understand just how good the kind of models are that a developer could run either locally or on a shared local inference server? To do that we used the OCaml tutorial problems first year Computer Science students at the university tackle on the Foundations of Computer Science course taught by Anil and Jon. These are interactive jupyter notebooks where students populate answer cells and their solutions are automatically checked. Each tutorial is known as a 'tick' and has one or more questions. Students must complete earlier questions in order to progress to later questions. There are also 'starred' ticks which are essentially stretch goals and harder than the non-starred ones.
Terminology
A quick bit of terminology that will help in the later sections:
Tokens are the units that Large Language Models take as input and output. A token is roughly three quarters of a word in length on average and they come from a fixed vocabulary for a given model. Here's Deepseek R1's vocab (warning it's about 8mb of json).
Reasoning models or a thinking mode when the model is given some space in which to reason through its approach to the problem before it generates an answer. After pre-training on very large text corpora reasoning models undergo a phase of Reinforcement Learning. If you want to know more, Sebastian Raschka has a great overview article. The latest Qwen3 models from Alibaba have the ability to selectively enable thinking mode. This lets you trade off latency and performance. More on this later.
OpenRouter is a marketplace for LLM providers. It provides a unified OpenAI-compatible API and then routes requests to different model providers based on the model you specify and any filtering options (e.g., no training on data, support for certain features). If you only use proprietary models then this is less interesting, they are often only available via a small handful of APIs that largely have similar pricing (e.g., for Gemini you can go via the Gemini or Vertex API). If you use open weights models though, there are a plethora of providers all competing on price, latency and throughput. For example if you want Llama 3.3 70B you can currently choose the cheapest (inference.net) at $0.10 per million tokens input and $0.25 per million tokens output with 1.02s time-to-first-token and 28.41 tokens per second throughput. On the other hand, if throughput is your primary concern then there's Groq at 372.2 tokens per second but you'll pay a premium at $0.59 in and $0.79 out.
Distillation is when you use the output of a much larger model to improve the performance of a smaller model. When releasing Deepseek-R1, Deepseek also released a series of smaller (originally non-Deepseek) models that had been fine-tuned on the outputs of Deepseek-R1.
Mixture of experts is a type of architecture where only a subset of the network weights are activated for each token processed. This can lead to a performance win at inference time and is in contrast to a dense model in which every process token interacts with every non-embedding model parameter.
Models
We took the following open weight models, using instruct variants models where available:
- Google Gemma3 12B and 27B
- Deepseek-R1-Llama 70B
- Meta Llama-3.1 8B and 70B
- Microsoft Phi-4
- Mistral 8B
- Mistral Nemo (12B)
- Mistral Small 24B
- Qwen 2.5 7B and 72B
- Qwen 2.5 Coder 7B and 32B
- Qwen 3 8B, 14B, 32B and 30BA3B (Thinking and non-thinking)
We gave models a similar setup to students. Each model had 3 attempts to complete each question by producing a code block that would pass the notebook's tests. If they produced a passing block of code they proceeded to the next question. We repeated this 5 times per model per tick. We used OpenRouter for inference.
The tick questions tested a range of concepts such as recursion, data structures, streams etc.. We'll look at them in more depth in the results.
Results
Here's a graph of the success rate against parameter count for all models. Note the logarithmic x-axis:
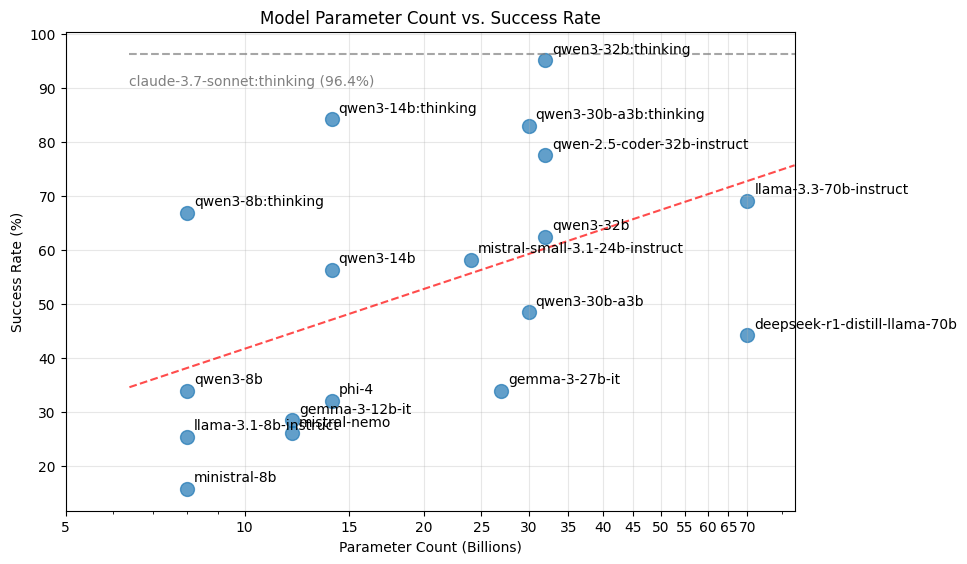
And a table of overall success rate. This is the percentage of tick-question pairs that a model was able to solve given 3 attempts.
| Model | Overall Success Rate |
|---|---|
| anthropic/claude-3.7-sonnet:thinking | 96.4% |
| qwen/qwen3-32b:thinking | 95.2% |
| qwen/qwen3-14b:thinking | 84.2% |
| qwen/qwen3-30b-a3b:thinking | 83.0% |
| qwen/qwen-2.5-coder-32b-instruct | 77.6% |
| meta-llama/llama-3.3-70b-instruct | 69.1% |
| qwen/qwen3-8b:thinking | 66.9% |
| qwen/qwen3-32b | 62.4% |
| mistralai/mistral-small-3.1-24b-instruct | 58.2% |
| qwen/qwen3-14b | 56.4% |
| qwen/qwen3-30b-a3b | 48.5% |
| deepseek/deepseek-r1-distill-llama-70b | 44.2% |
| google/gemma-3-27b-it | 33.9% |
| qwen/qwen3-8b | 33.9% |
| microsoft/phi-4 | 32.1% |
| google/gemma-3-12b-it | 28.5% |
| mistralai/mistral-nemo | 26.1% |
| meta-llama/llama-3.1-8b-instruct | 25.5% |
| mistral/ministral-8b | 15.8% |
High-level takeaways
Qwen 3 models performed very well The best performing model was qwen3-32b in thinking mode at 95.2%. This is very close to Anthropic's Claude 3.7 Sonnet with thinking. At Qwen3 32B's current $0.10 per million input tokens and $0.30 per million output tokens this is up to 50x cheaper than Claude 3.7's $3 M in / $15 M out pricing. Even better the Qwen3 32B model is Apache2 licensed and so can be self-hosted. In addition, all Qwen3 models in non-thinking mode outperformed comparably-sized models from other families.
Qwen2.5's coding variant was the best non-thinking model. The Qwen2.5-Coder-32B model performed well at 77.6% and was the best non-thinking model. It outperformed Qwen3 32B and this means the upcoming Qwen3-Coder model should be very strong.
Qwen3 with thinking on performed better than non-thinking variants. In every case allowing Qwen3 to think significantly improved performance. The qwen3-8b model with thinking on was very close in performance to llama-3.3-70b, a model almost an order of magnitude larger. Note though that this comes at the expense of increased latency and cost. In most cases thinking added 2-3,000 tokens of reasoning before the model produced its final answer, for Qwen3 32B on openrouter that is roughly a minute of thinking. There were also cases where the model entered a loop and kept reasoning until it hit the token limit.
The Qwen3 30B-A3B MoE model could be a good compromise Whilst it has 30 billion parameters the MoE model only activates about 3 billion of them for each token processed. This can be a substantial performance win when doing inference and indeed you can see the throughput ratio on OpenRouter between Qwen3 32B and Qwen3 30B-A3B. I suspect that gap will widen as providers do more optimisation of their MoE serving code.
Within a family more parameters means better performance. Within the Gemma and Qwen families, larger parameter counts generally led to better performance, as seen in the graph. Presumably there is some OCaml in the pretraining corpus and the larger models have a higher chance of retaining information from it?
Deepseek R1's distilled Llama 3.3 70B reasoning model did not beat base model. The Deepseek-R1-Llama-3.3-70B model which was produced by Deepseek by distilling from their large Deepseek R1 model had worse performance than the model it was based on Llama-3.3-70B.
What went wrong?
There were some consistent themes amongst failures across especially the smaller models. Here are some of the most common:
Syntax errors
Many models had basic syntax errors in their solutions, such as incorrect comment syntax or a lack of in. There were also cases of incorrect function application syntax. A very common mistake was not including rec for recursive functions.
Type system confusion
On several of the tick questions this involved confusing the int and float operators (+/+., /.). A common pattern was changing just one of the operators in response to a compile error, then changing another on the next error, etc..
Hallucinated functions
Some failures came from hallucinating functions such as List.sub or List.combinations, as well as assuming things like Core and Format were available. This is curious as even small models (like Qwen2.5-Coder-7B) assumed Core was available and yet still made fundamental OCaml syntactic errors.
Recursion
Beyond the failure to include rec the models struggled with recursion. There were several incorrect base cases in questions involving streams which resulted in a fair bit of non-termination in those questions. It would be interesting to try rewriting some of the tick questions as iterative and seeing whether success rates increase.
Limitations
These are only introductory tasks aimed at first year Computer Science students and so are not representative of the complexity of larger OCaml codebases that may also use advanced language features.
Summary
Qwen3 had an impressive showing. I had actually already written a draft of this blog post before Qwen3 was released, and re-running the evaluation to include it led to a very different outcome!
So what next? It would be interesting to understand where the gap in performance is when thinking mode is on and off. Are there common mistakes Qwen3 is making when thinking is off?
As a next step we clearly need to move beyond first-year Computer Science questions, especially as the top models are already saturating on this test. Anil reports performance on OCaml vibe-coded projects through Claude lags behind its abilities in Python.
Next, how do we improve their performance? For this we really need more data. We now have a dataset of OCaml code extracted from opam that is regularly updated but still small (~80k ml/mli files) and it is unclear as to the difficulty level of each bit of code. This is important because there is good evidence (Sun et al, Ji et al) that going from easy to difficult examples when training via reinforcement learning can improve performance.
One promising avenue is Cassano et al who have done some work leveraging training data from 'high resource' languages to generate code and validation tests in target 'low resource' languages. This approach could be extended to novel language features, as well as being used for reinforcement learning rather than just fine-tuning.
Unrelated to OCaml, I'm looking forward to testing out how these models perform on the Conservation Evidence work that Anil and I are involved in. We currently self-host Deepseek-R1-Llama-3.3-70B and switching to Qwen3 32B could substantially improve the performance at one of our crucial bottlenecks.